This is the fourth of twelve articles in a series called Operationally Scalable Practices. The first article gives an introduction and the second article contains a general overview. In short, this series suggests a comprehensive and cogent blueprint to best position organizations and DBAs for growth.
This article – building a standard platform – has been broken into three parts. We’ve already discussed standardization in general and looked in-depth at storage. Now it’s time to look in-depth at three more key decisions: CPU and memory and networking.
Consolidation
One of the key ideas of Operationally Scalable Practices is to start early with standards that don’t get in the way of consolidation. As you grow, consolidation will be increasingly important – saving both money and time. Before we dig into specifics of standardizing CPU and memory, we need to briefly discuss consolidation in general.
Consolidation can happen at many levels:
- Single schema and multiple customers
- Single database and multiple schemas or tenants (12c CDB)
- Single OS and multiple databases
- Single hardware and multiple OS’s (virtualization)
Two important points about this list. First, it works a lot like performance tuning: the biggest wins are always highest in the stack. If you want to save time and money then you should push to consolidate as high as possible, ideally in the application. But there are often forces pushing consolidation lower in the stack as well. For example:
- Google doesn’t spin up new VMs every time a new customer signs up for Google Apps. Their existing webapp stack handles new customers. This is a great model – but if your app wasn’t designed this way from the beginning, it could require a massive development effort to add it.
- It’s obvious but worth stating: you can only push consolidation up a homogenous stack. If the DB runs on linux and the app runs on windows then naturally they’ll each need their own VM. Same goes for the other three tiers.
- Server operating systems have robust multiuser capabilities – but sharing an Operating System can still be tricky and these days virtualization offers a strong value proposition (especially when combined with automation). Then there are containers, which fall somewhere in between single OS and virtualization.
- Security or regulatory or contractual requirements may require separate storage, separate databases or separate operating systems.
- A requirement for independent failover may drive separate databases. In data guard, whole databases (or whole container databases) must be failed over as a single unit.
The second important point is that realistically you will encounter all four levels of consolidation at some point as you grow. Great standards accommodate them all.
CPU
In my opinion, batch workloads can vary but interactive workloads should always be CPU-bound (not I/O-bound). To put it another way: there are times when your database is mainly servicing some app where end-users are clicking around. At those times, your “top activity” graph in enterprise manager should primarily be green. Not blue, not red, not any other color. (And not too much of that green!) I’m not talking about reports, backups, or scheduled jobs – just the interactive application itself. (Ideally you even have some way to distinguish between different categories of activity, in which case there are ways to look at the profile of the interactive traffic even when there is other activity in the database!)
This leads into the question of how much CPU you need. I don’t have any hard and fast rules for CPU minimums in a standard configuration. Just two important thoughts:
- Maximum unit of consolidation: CPU is a major factor in how many applications can be consolidated on a single server. (Assuming that we’re talking about interactive applications with effective DB caching – these should be primarily CPU-bound.)
- Minimum unit of licensing: If partitioning or encryption becomes a requirement for you six months down the road then you’ll have to license the number of cores in one server. Oracle requires you to license all CPUs physically present in the server if any feature is used on that server.
The goal is to limit future purchasing to this configuration. And as with storage, if you really must have more than one configuration, then try to keep it down to two (like a high-CPU option).
Memory
I don’t have a formula to tell you how much memory you should standardize on either. It’s surprising how often SGAs are still poorly sized today – both too small and too large. You need to understand your own applications and their behavior. It’s worthwhile to spend some time reading sar or AWR reports and looking at historical activity graphs.
Once you start to get a rough idea what your typical workload looks like, I would simply suggest to round up as you make the final decision on standard total server memory capacity. There are two reasons for this:
- OS and database consolidation have higher memory requirements. Application and schema/multitenant consolidation will not be as demanding on memory – but as we pointed out earlier, your standards should support all levels of consolidation.
- You’re probably not maxing out the memory capacity of your server and it’s probably not that expensive to bump it up a little bit.
| Consolidation Level | Common Bottleneck |
|---|---|
| Single Schema (Multiple Customers) | CPU |
| Multiple Schemas/PDBs | CPU |
| Multiple Databases | Memory |
| Multiple OS’s (VMs) | Memory |
Networking
Small companies generally start with one network. But these days, networking can quickly get complicated even at small companies since network gear allows you to define and deploy multiple logical networks on the physical equipment. Early on, even if it doesn’t all seem relevant yet, I would recommend discussing these networking topics:
- Current traffic: Are you gathering data on current network usage? Do you know how much bandwidth is used by various services, and how bursty those services are?
- Logical segregation: Which network should be used for application traffic? What about monitoring traffic, backup traffic, replication traffic (e.g. data guard or goldengate) and operations traffic (kickstarts, data copies between environments, etc)? What about I/O traffic (e.g. NFS or iSCSI)? What is the growth strategy and how will this likely evolve over the coming years?
- Physical connections: How many connections do we need, accounting for redundancy and isolation/performance requirements and any necessary physical network separation?
- Clustering: Clustering generally require a dedicated private network and tons of IPs (on both the private cluster network and your corporate network). Sometimes it has higher bandwidth and latency requirements than usual. Generally it is recommended to deploy RAC on at least 10G ethernet for the interconnect. Is there a general strategy for how this will be addressed when the need arises?
It will benefit you greatly to take these discussions into consideration early and account for growth as you build your standard platform.
Slots
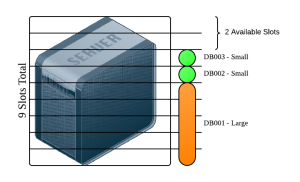
One design pattern that I’ve found to be helpful is the idea of slots. The basic idea is similar to physical PCI or DIMM slots – but these are logical “slots” which databases or VMs can use. This is a simplified, practical version of the service catalog concept borrowed from ITIL for private cloud architectures – and this can provide a strong basis if you grow or migrate to that point.
- Determine the smallest amount of memory which a standardized database (SGA) or VM will use. This will determine a slot size.
- Determine the largest amount of memory which can be allocated on the server. For databases, about 70% of server memory for SGA is a good starting point if it’s an interactive system. For VMs it’s possible to even allow more memory than is physically present but I don’t know the latest conventional wisdom about doing this.
- Choose additional DB or VM size options as even multiples of the minimum size.
For example, a database server containing 64GB of memory might have a slot size of 5GB with 9 total available slots. Anyone who wants a database can choose either a small or large database; a small database uses 1 slot and its SGA is 5GB. A large database uses 5 slots and its SGA is 25GB.
After the basic slot definition has been decided, CPU limits can be drafted. If the database server has 8 physical cores then the small database might have a hard limit of 2 CPUs and a large database might have a hard limit of 6 CPUs.
One area which can be confusing with CPU limits is factoring in processor threads. When determining your limits for a consolidation environment, make sure that individual applications are capped before pushing the total load over the physical number of CPUs. But allow the aggregate workload to approach the logical number of CPUs in a period of general heavy load coming from lots of applications.
In practice, that means:
- For multiple databases, set cpu_limit on each one low according to the physical count and calibrate the aggregate total against the logical count.
- For multiple schemas in a single database: use resource manager to limit CPU for each schema according to physical count and set cpu_count high according to logical count.
Now you have a first draft of memory and CPU definitions for a small and large database. The next step is to define the application workload limits for each database size. As you’re consolidating applications into a few databases, how many instances of your app can be allowed in a small and large database respectively?
Suppose you’re a SAAS company who hosts and manages lots of SAP databases for small businesses. I don’t actually know what the CPU or memory requirements of SAP are so I’m making these numbers up – but you might decide that a small database (5GB/2cpu) can support one SAP instance and a large database (25GB/6cpu) can support 25 instances (with PDBs).
Remember that schema/multi-tenant consolidation is very efficient – so you can service many more applications with less memory compared to multiple databases. For a starting point, make sure that the large database uses more than half of the slots then use server CPU capacity to determine how many app instances can be serviced by a large database.
Another observation is that your production system probably uses more CPU than your test and dev systems. You may be able to double or triple the app instance limits for non-production servers.
It’s an iterative process to find the right slot sizes and workload limits. But the payoff is huge: something that’s easy to draw on a whiteboard and explain to stakeholders. Your management has some concrete figures to work with when projecting hardware needs against potential growth. The bottom line is that you have flexible yet strong standards – which will enable rapid growth while easing management.
Example Slot Definitions
| Database Size | Slots | Max SAP Instances (Production Server) | Max SAP Instances (Test Server) |
|---|---|---|---|
| Small | 1 | 1 | 2 |
| Large | 5 | 25 | 50 |
Standard Server: - 8 Cores - 64 GB Memory - 9 Slots nr_hugepages = 23552 (45 GB plus 1 GB extra)
Standard Database: sga_target/max_size = [slots * 5] GB pga_aggregate_target = [slots * 2] GB cpu_count = [slots + 1] processes = [slots * 400]


















